Robot stops. You SSH in. Now what?
Your robot stops moving in the field. You SSH in, run ros2 topic echo /diagnostics, and get a wall of text scrolling faster than you can read. Something flashes ERROR for half a second. Then OK. Then ERROR again. Gone before you can even copy-paste it.
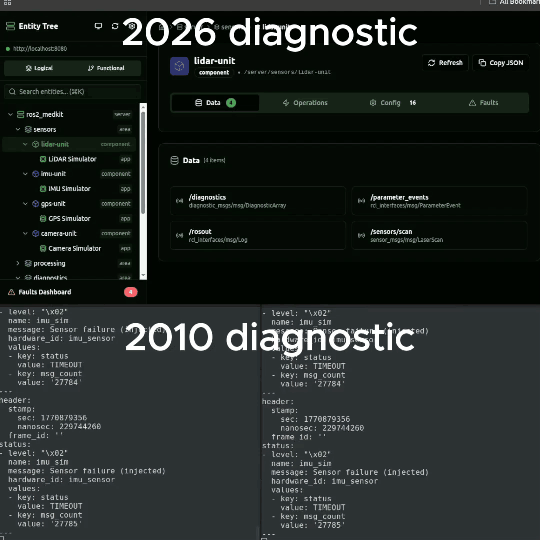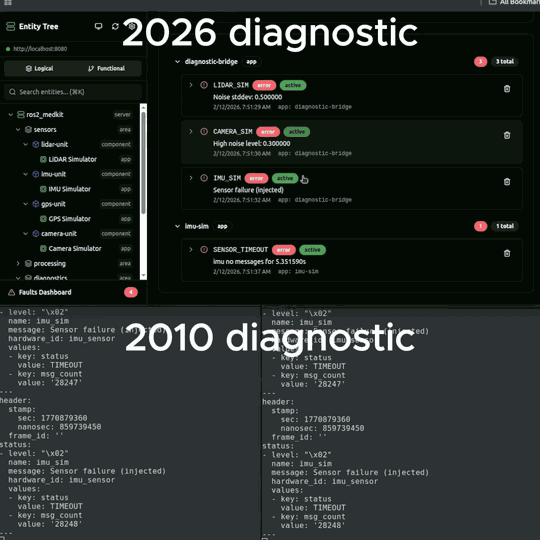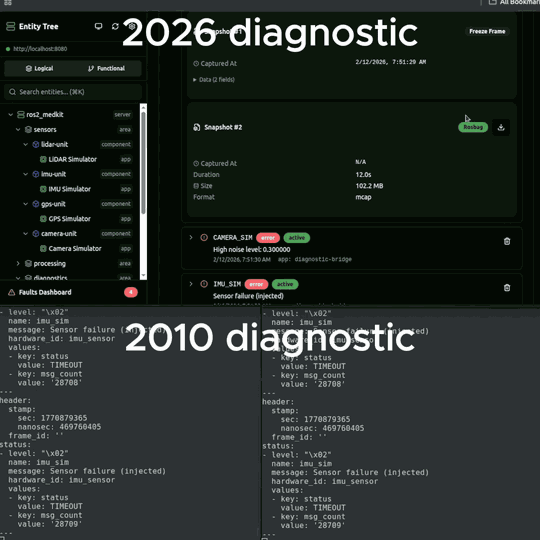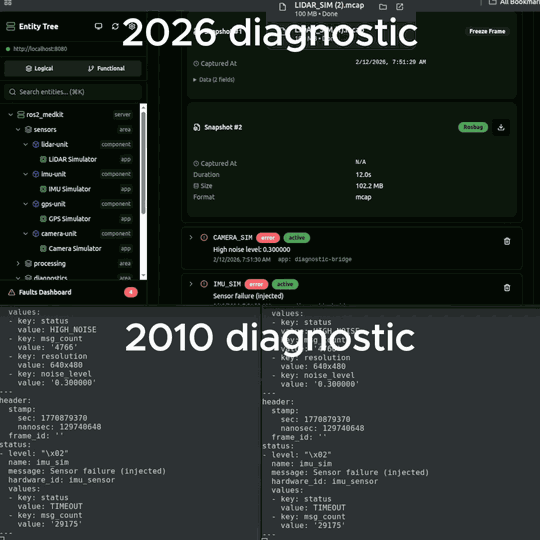
This is the state of diagnostics for most ROS 2 robots in production. The diagnostic system (REP 107) was designed in 2010 for a single robot on a lab bench. It publishes key-value pairs on a topic. No structure, no fault lifecycle, no snapshots, no history. Just a stream of messages that disappears as fast as it arrives.
Now multiply that by 20 robots at a customer site. At 2 AM. When you cannot reproduce the issue.
Automotive solved this 30 years ago
In 1996, OBD-II standardized how cars report faults. Every car, every manufacturer, same diagnostic interface. A mechanic plugs in a scan tool, reads structured fault codes, checks freeze-frame data captured at the moment of failure, and clears the fault after repair.
No grepping through logs. No guessing. Structured data, standardized access, captured at the right moment.
Automotive diagnostics kept evolving - from OBD-II through UDS to today's SOVD (Service-Oriented Vehicle Diagnostics). Each generation added more structure, better APIs, and support for increasingly software-defined systems.
Robotics skipped all of that. We went straight from "print to stdout" to "stream everything to the cloud and search later..."
What SOVD actually is
SOVD is a diagnostic standard from ASAM that replaces binary protocols with a REST/JSON API. It was designed for software-defined vehicles, but the model maps directly to any distributed system - including ROS 2 robots.
Three core ideas:
1. Entity tree - your system describes itself
SOVD organizes every diagnosable element into a four-level hierarchy: Areas (physical or logical domains), Components (hardware or software units), Apps (individual ROS 2 nodes), and Functions (capabilities that cut across components).

A small robot might have a single area. A large robot uses areas to separate domains - base, navigation, arm, safety - each containing its own components and apps. Functions like localization can depend on apps from both navigation and base, giving you a capability-oriented view alongside the physical hierarchy.
The entity tree is self-describing. Query the API and you get the full structure of what is running, what each component does, and how they relate. No documentation needed, no SSH required.
2. Structured faults with context
Instead of a diagnostic message that says "ERROR" and disappears, SOVD faults have:
- Fault code - a stable identifier (not a free-text string that changes between releases)
- Severity - INFO, WARN, ERROR, CRITICAL
- Lifecycle - confirmed, healed, cleared (with debounce filtering, not just on/off)
- Occurrence tracking - when it first appeared, how many times, when it last recurred
- Freeze-frame snapshots - exact sensor values at the moment of failure
- Rosbag capture - black-box recording of all related topics before and after the fault
The freeze-frame is the most important part. When a fault triggers, the system captures what every relevant sensor was reading at that exact moment. Two hours later when the engineer looks at it, the data is still there - not scrolled off the terminal, not rotated out of journalctl.
3. REST API - no SSH, no custom tooling
Every piece of diagnostic data is accessible through standard HTTP:
# What is running on this robot?
curl http://robot-01:8080/api/v1/components
# What faults are active?
curl http://robot-01:8080/api/v1/components/lidar_driver/faults
# What were the sensor readings when the fault occurred?
curl http://robot-01:8080/api/v1/components/lidar_driver/faults/LIDAR_FAILURESame API for every robot. Same API for web dashboards, AI assistants, fleet management tools, CI pipelines. No SSH keys to manage, no custom scripts per robot model, no proprietary tools.
Telemetry vs diagnostics: two different views
Most teams start with telemetry - stream everything to Prometheus/Grafana and search when something breaks. This works for a prototype, but the cost scales fast. A single robot with 30 topics at 10 Hz generates ~26 million messages per day. A fleet of 50 robots is 1.3 billion messages. That is real bandwidth, real storage, and real compute - most of it for data nobody ever looks at.
SOVD diagnostics take the opposite approach. Instead of streaming everything and searching later, you capture structured data on-demand and at fault time.
| Telemetry | Diagnostics (SOVD) | |
|---|---|---|
| Direction | Push (device to cloud) | Interactive (request/response) |
| Cost pattern | Grows with fleet size | Flat baseline, spikes on faults |
| Best for | Trends, dashboards, alerting | Root cause analysis, fault context |
| Data volume | High (all signals, all the time) | Low (targeted, on-demand) |
The practical answer is both: push a small telemetry baseline for dashboards and alerting, pull rich diagnostic data on-demand when something goes wrong. Freeze-frames and rosbag captures give you the depth of full telemetry at the cost of targeted snapshots.
ros2_medkit: SOVD for ROS 2
ros2_medkit is our open-source implementation of SOVD for ROS 2. It runs as a gateway on the robot and exposes the full diagnostic API:
- Entity tree - auto-discovers ROS 2 nodes, organizes them into areas/components/functions
- Fault manager - debounce-based lifecycle, freeze-frame snapshots, rosbag black-box capture
- REST/SSE gateway - standard HTTP API with OpenAPI spec and Swagger UI
- Triggers - condition-based rules that fire on thresholds, value changes, or faults
- Remote scripts - upload and execute diagnostics without SSH
- Resource locking - prevent config conflicts between engineers
- Log aggregation - per-entity log access via API, no more journalctl across N nodes
The gateway also ships an MCP adapter that gives LLMs read-only access to the diagnostic API - enabling AI-assisted root cause analysis with human-in-the-loop approval.
For the full feature breakdown, see the 0.4.0 release deep dive.
What this means for operations
The shift from "SSH and grep" to "REST API with structured faults" changes how teams scale:
- One interface for everything. Robots, PLCs, sensors - all accessible through the same API. No more switching between tools per subsystem.
- Self-documenting incidents. Freeze-frames and rosbag captures happen automatically. The data is ready before anyone opens a terminal.
- Fleet-level visibility. VDA 5050 fleet managers get flat errors for routing. Engineers get deep diagnostics for root cause. Same fault, two views.
- Scale without headcount. Triggers, remote scripts, and structured faults let a small team manage a growing fleet without proportionally growing the on-call rotation.
Get started
git clone https://github.com/selfpatch/ros2_medkit.git
cd ros2_medkit
pixi install && pixi run build
pixi run startOpen http://localhost:8080/docs for the Swagger UI. Every ROS 2 entity in your workspace is now accessible through a standard REST API.
Need help integrating medkit into your fleet? Let's talk.


