Same fault, two views
Your fleet manager gets this from VDA 5050:
{
"errorType": "LIDAR_FAILURE",
"errorLevel": "FATAL",
"errorDescription": "Lidar scan degraded on front sensor",
"errorReferences": [
{ "referenceKey": "nodeId", "referenceValue": "node_7" }
]
}Four fields. The robot stopped at node 7. Error says LIDAR_FAILURE. Now what?
Your engineer gets this from SOVD via ros2_medkit:
{
"item": {
"code": "LIDAR_FAILURE",
"fault_name": "Scan point count below minimum threshold",
"severity": 3,
"status": { "value": "CONFIRMED" }
},
"environment_data": {
"snapshots": [
{
"type": "freeze_frame",
"timestamp": "2026-01-12T22:47:03Z",
"data": {
"valid_scan_count": 191,
"expected_scan_count": 220,
"scan_frequency_hz": 9.7,
"temperature_celsius": 48.2,
"uptime_hours": 312.4
}
},
{
"type": "rosbag",
"timestamp": "2026-01-12T22:47:03Z",
"bulk_data_uri": "/api/v1/components/lidar_front/bulk-data/rosbags/LIDAR_FAILURE"
}
],
"extended_data_records": {
"first_occurrence": "2026-01-12T20:30:14Z",
"last_occurrence": "2026-01-12T22:47:03Z"
}
},
"x-medkit": {
"occurrence_count": 3,
"severity_label": "CRITICAL",
"reporting_sources": ["/sensors/lidar_front"]
}
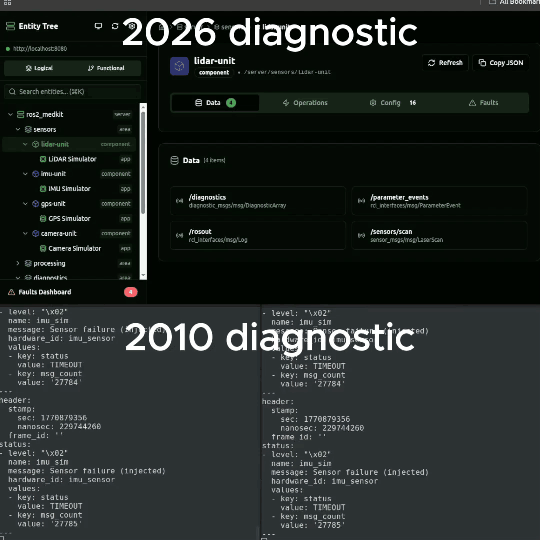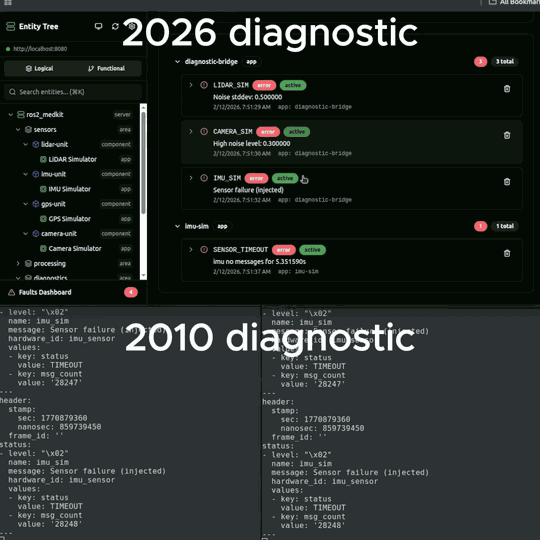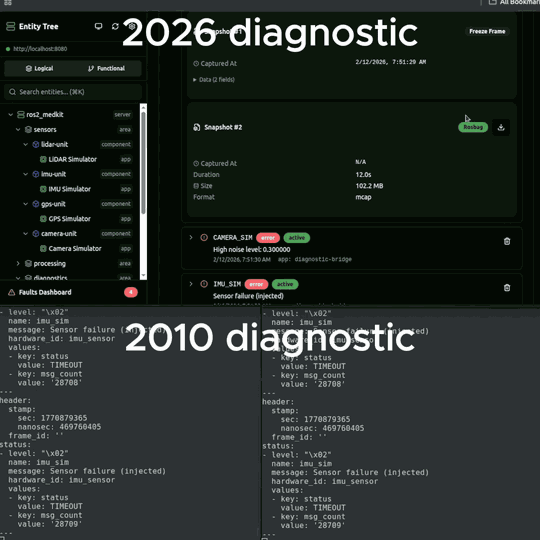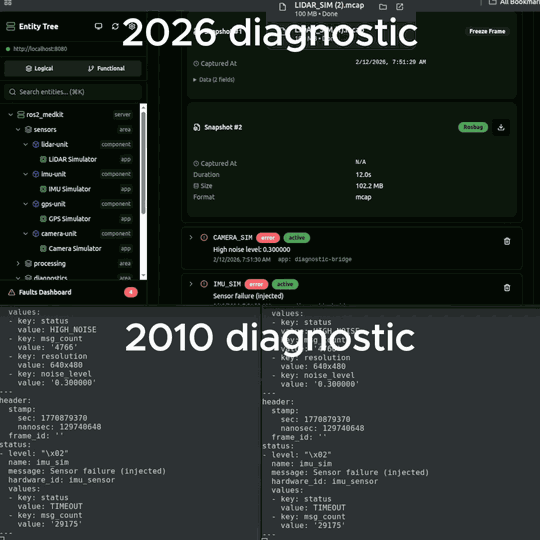
}Severity is CRITICAL (3). The fault recurred 3 times since 20:30. The freeze-frame snapshot shows valid scan count at 191 (expected 220), temperature at 48.2C after 312 hours of uptime. A rosbag black-box recording captured all related topics around the moment of failure.
One is enough to reroute the fleet. The other is enough to fix the robot.
Why VDA 5050 errors are flat
This is not a design flaw. VDA 5050 was built for fleet coordination: orders, routes, state machines. Its error model is intentionally minimal.

VDA 5050 gives the fleet manager 4 fields (errorType, errorLevel, description, references) - enough to reroute orders. SOVD gives the engineer everything needed to diagnose root cause without SSH.
VDA 5050 carries just enough for routing decisions. Asking it to carry diagnostic depth would bloat the protocol and violate its design principles. The right answer is two protocols, each doing what it does best.
Architecture: two protocols, one robot
The bridge between VDA 5050 and SOVD runs as two separate ROS 2 processes on the robot. They share data through standard ROS 2 interfaces, not custom hacks.

The VDA 5050 agent is a standard ROS 2 node that subscribes to ros2_medkit's fault topics and calls its services. When a new fault appears, the agent:
- Reads the full SOVD fault record from ros2_medkit
- Maps it to VDA 5050's error model (severity CRITICAL becomes errorLevel FATAL, WARNING stays WARNING)
- Attaches the fault ID as an
errorReferenceso it can be correlated later - Publishes the updated VDA 5050 state message over MQTT
The mapping is lossy by design. The fleet manager does not need freeze frames. It needs to know this robot should be pulled from active orders.
Note
The VDA 5050 agent does not replace your existing fleet integration. It adds a diagnostic-aware error layer on top of whatever VDA 5050 adapter you already run. The agent reads from ros2_medkit, not from your fleet controller.
Watch it in action - VDA 5050 mission with a LiDAR fault and full SOVD diagnostics:
Freeze frames: what was happening at failure time
Freeze frames capture a snapshot of relevant sensor and system data at the exact moment a fault triggers. This is borrowed from automotive diagnostics and adapted for ROS 2.
When ros2_medkit's fault manager detects a new fault condition, it:
- Queries all data sources registered for that component
- Captures current values into a timestamped snapshot
- Stores up to N freeze frames per fault (configurable, default 5)
- Saves a rosbag black-box recording - a configurable rolling buffer that captures data before and after the fault, not just from the moment of detection. Like an airplane black box, the interesting data is what happened in the seconds leading up to the failure
# Retrieve fault detail with environment data snapshots via REST
curl http://robot-01:8080/api/v1/components/lidar_front/faults/LIDAR_FAILURE | jq '.'To illustrate: in this example the freeze frame tells the engineer that scan count was 191 (expected 220), frequency had dropped to 9.7 Hz (nominal 10 Hz), and the sensor was at 48.2C after 312 hours of continuous operation. That pattern - gradual degradation plus elevated temperature plus high uptime - would point to thermal-related sensor aging, not a sudden hardware failure.
Without the freeze frame, the engineer SSHes into the robot, greps through logs, and tries to reconstruct what the sensor readings were 2 hours ago. If the logs rotated, they are out of luck.
Beyond snapshots: tracking degradation across the fleet
Freeze frames tell you what happened at fault time. But the real power comes from comparing across robots. If robot-47's LIDAR scan count dropped from 220 to 191 over 312 hours of uptime, how do the other robots in your fleet look? Which ones are on the same trajectory?
ros2_medkit tracks first and last occurrence timestamps and occurrence counts for every fault. Combined with freeze-frame data across the fleet, you can spot patterns: the same sensor degradation at similar uptime hours, the same temperature profile before failure. That is predictive maintenance built from diagnostic data you already have.
Data flow: from fault to fleet reroute
Here is what happens end-to-end when the front LIDAR degrades on robot-47:
- ros2_medkit fault manager detects
/sensors/lidar_frontdiagnostic status crossing the fault threshold - Fault record created with fault code, freeze-frame snapshot, rosbag capture started
- VDA 5050 agent receives fault notification via ROS 2 topic
- Agent maps fault to VDA 5050 error:
errorType: LIDAR_FAILURE,errorLevel: FATAL - Fleet manager (InOrbit, FreeFleet, your custom stack) receives updated state over MQTT
- Fleet manager reroutes remaining orders away from robot-47, flags it for service
- Engineer opens medkit REST API or web UI, pulls full fault details, downloads rosbag
- Engineer diagnoses root cause from freeze-frame data - manually through the REST API/web UI, or with AI assistance via the MCP adapter that gives an LLM read-only access to the same diagnostic data
Steps 1-6 happen within seconds. The fleet keeps moving. The engineer works the root cause on their own timeline, not at 2 AM with SSH.
Tip
The VDA 5050 error includes the fault code (LIDAR_FAILURE) as an errorReference. This lets the engineer go straight from the fleet manager alert to the full SOVD fault record without searching through logs.
Two standards, zero conflict
VDA 5050 is the fleet language. SOVD is the diagnostics language. They solve different problems at different layers of the stack.
Trying to make VDA 5050 carry diagnostic depth would mean extending a fleet coordination protocol with freeze frames, entity trees, and rosbag URIs. Every fleet manager would need to understand that data.
The bridge approach keeps both protocols focused on their strengths. The fleet manager gets flat, actionable errors. The engineer gets structured, deep diagnostic records. Same fault, two views, and each side evolves independently.
What this means for operations
Without the bridge, every VDA 5050 error requires someone to SSH into the robot and reconstruct what happened. With it, the fleet manager reroutes automatically and the diagnostic record is ready before anyone opens a terminal. Incidents that used to block an engineer for hours become self-documenting.
The diagnostic gateway (ros2_medkit) is open source under Apache 2.0. The VDA 5050 agent that bridges medkit faults to fleet managers is part of the selfpatch enterprise platform.
If you are already running ros2_medkit on your robots, the SOVD diagnostic layer is ready. The VDA 5050 bridge adds fleet-level integration on top - get in touch to discuss your fleet setup.
For the full list of production features added in the latest release, see ros2_medkit 0.4.0 release notes. If your factory also runs PLCs, see how the OPC-UA bridge brings PLC faults into the same diagnostic system.